Problem
Given a string S and a string T, count the number of distinct subsequences of T in S.
A subsequence of a string is a new string which is formed from the original string
by deleting some (can be none) of the characters
without disturbing the relative positions of the remaining characters.
(ie, "ACE" is a subsequence of "ABCDE" while "AEC" is not).
Example
Given S = "rabbbit", T = "rabbit", return 3.
思路
- 为什么需要从暴力搜索想到动归?
- 因为这类型的搜索类似一个组合问题, 即从m个character中抽出n个与目标匹配, 所以复杂度为O(2^n)
- 因为存在overlap subproblem, 所以我们需要记录子状态.
- 这时候我们只需要知道子状态与父状态的关系式
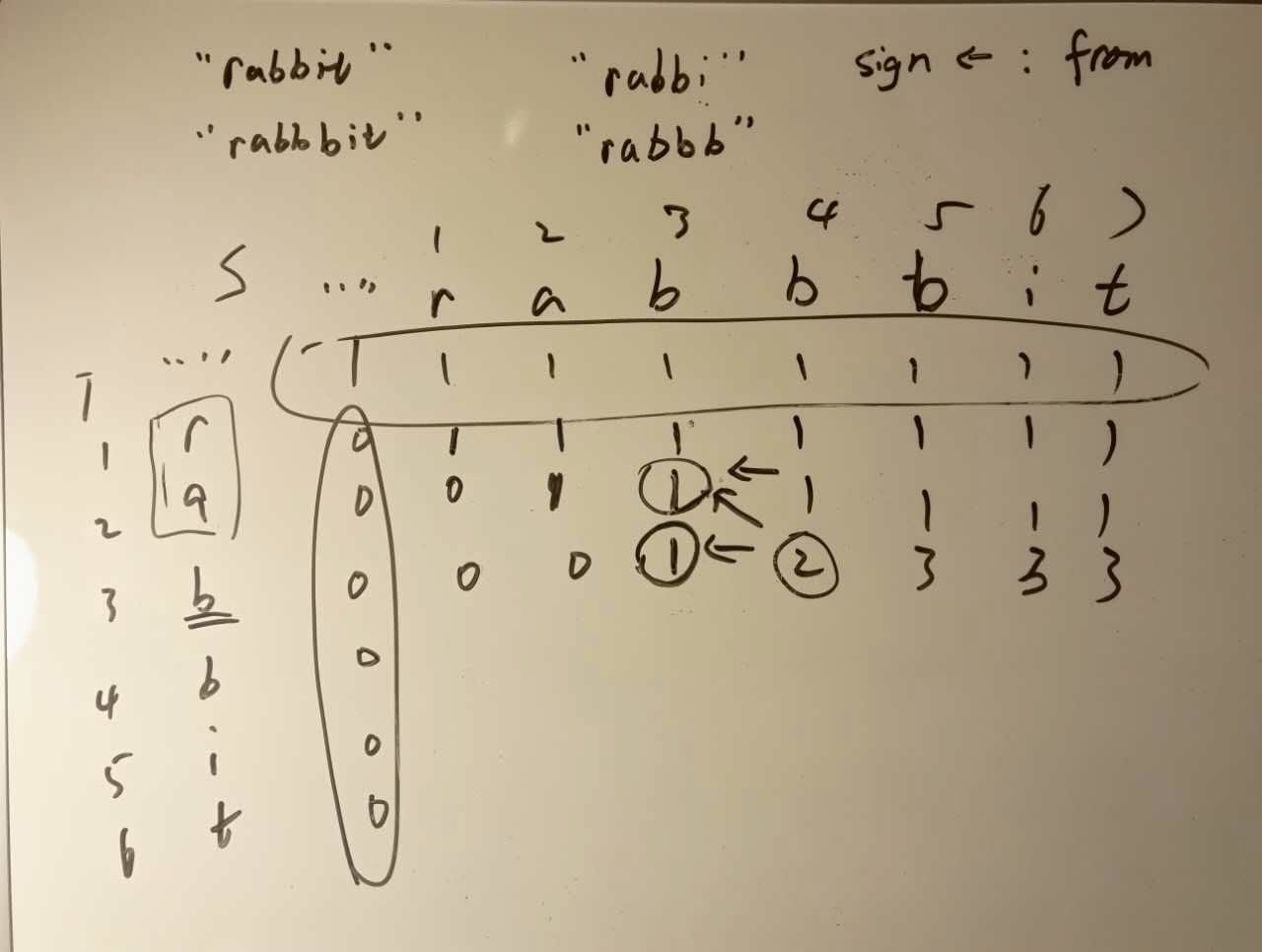
- 匹配矩阵
- if s(i) == t(j), 也就是图中s(4) == t(3)
- 那么dp[4][3] 来源于dp[3][2] 和dp[3][3]
- 问题: 为什么和dp[4][2]没有关系?
- 因为dp[4][2] 来源于 dp[3][2], 并且一模一样
- else s(i) != t(j), 也就是图中 s(5) != t(5)
- dp[5][5] 来源于 dp[4][5], 与 dp[4][4] , dp[5][4] 没有关系
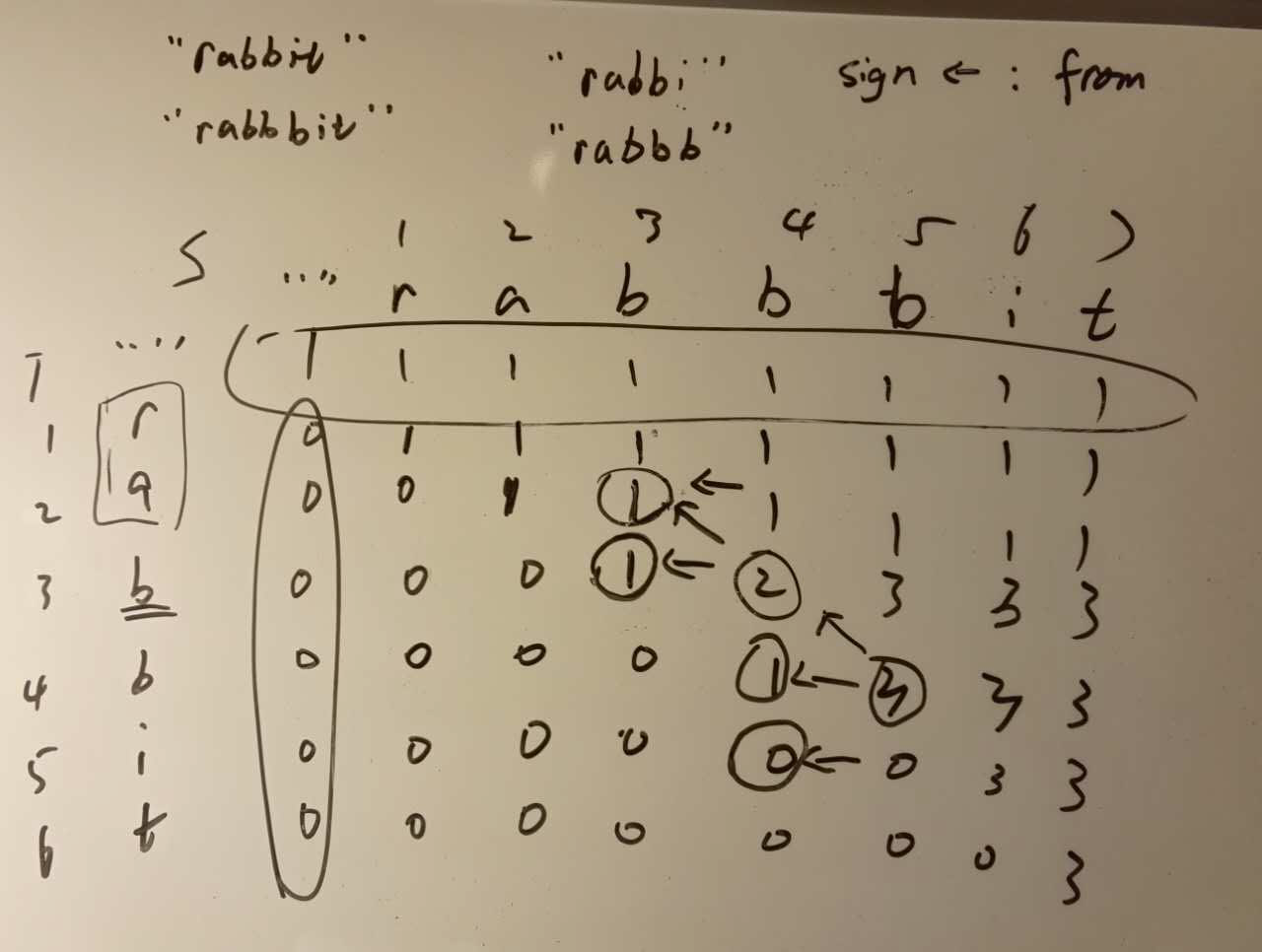
- 图中画椭圆的地方就是需要初始化的地方
- 写出state, function, initialize, answer四部曲
public int numDistinct(String S, String T) {
if (S == null || T == null) {
return 0;
}
int ls = S.length();
int lt = T.length();
int[][] dp = new int[ls + 1][lt + 1];
for (int i = 0; i <= ls; i++) {
dp[i][0] = 1;
}
for (int i = 1; i <= ls; i++) {
for (int j = 1; j <= lt; j++) {
if (S.charAt(i - 1) == T.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
} else {
dp[i][j] = dp[i - 1][j];
}
}
}
return dp[ls][lt];
}
滚动数组优化
public int numDistinct(String S, String T) {
if (S == null || T == null) {
return 0;
}
int ls = S.length();
int lt = T.length();
int[][] dp = new int[2][lt + 1];
dp[0][0] = 1;
for (int i = 1; i <= ls; i++) {
dp[i%2][0] = 1;
for (int j = 1; j <= lt; j++) {
if (S.charAt(i - 1) == T.charAt(j - 1)) {
dp[i%2][j] = dp[(i - 1)%2][j - 1] + dp[(i - 1)%2][j];
} else {
dp[i%2][j] = dp[(i - 1)%2][j];
}
}
}
return dp[ls%2][lt];
}